[Reference] 정규화
정규화
정규화는 쉽게 말해서 DB의 중복을 없애는 작업이다.
RDBMS는 중복이 되는 것들이 관계라는 것으로 서로 엮여있어서, 특정 데이터의 값이 변할경우 관련되어있는 모든 데이터가 전부 바뀌게 된다.
따라서, 중복을 제거할 필요가 있다는 것이다.
또한, 데이터가 많이 쌓일수록 속도가 느려지기 때문에 데이터를 최대한 압축할 필요가 있다.
정규화의 종류가 많은데, 실무에서는 일반적으로 1,2,3 정규화까지만 사용한다.
그리고, 정규화를 풀어버리는 경우도 존재하는데, 이것을 비정규화라고 부른다.
제 1 정규화(1NF)
1정규화에서는 값이 오직 1개씩만 들어가도록 만들어야 한다.
정규화 진행되기 전 테이블
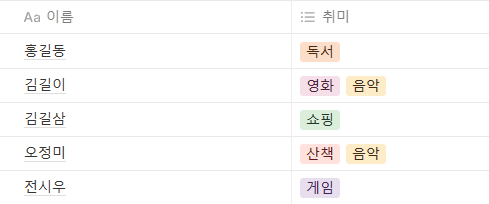
위 테이블에서는 취미에 여러 값이 들어가 있는데, 이것을 나눠주는 작업이 필요하다.
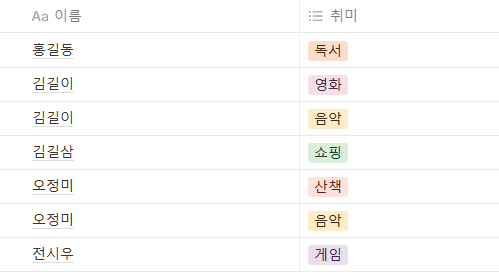
취미 카테고리 안에 값이 하나만 존재하지만, 이름이 중복되게 된다.
제 2 정규화(2NF)
2정규화는 1정규화에서 중복되는 값이 존재하면, 그것을 분리하여 참조하는 것이다.
정규화 진행되기 전 테이블

정규화 후 테이블

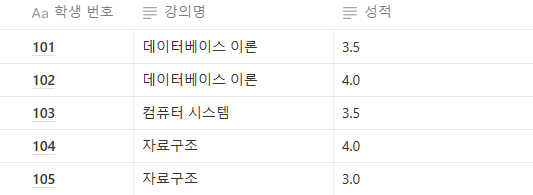
이 과정에서 이행적 함수 종속성 문제가 발생하는데, A->B, B->C, C->A 관계가 있는 것을 말한다.
이것을 완벽하게 분리하지 않을 경우 이상현상이 발생하게 된다.
제 3 정규화(3NF)
3정규화는 2정규화를 진행한 후 이행적 함수 종속성을 제거한 정규형이다.
결국은 모조리 다 분리하면 된다.
댓글남기기